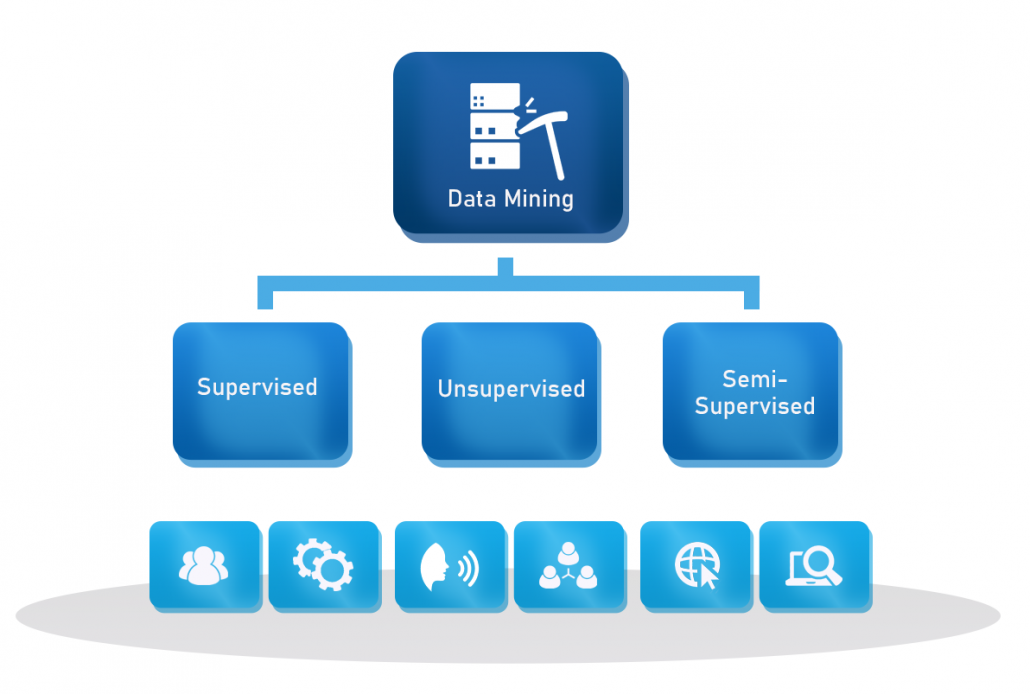
Supervised, Unsupervised and Semi-Supervised Data Learning Models
Data Mining has three main kinds of learning models – supervised, unsupervised, and semi-supervised. Data scientists choose the best fit model depending on the project objectives, the resources, and the data available.
Supervised Learning
Supervised learning models predict the value of observation through a single output variable. The primary goal is to be able to predict and classify information. When training a supervised learning algorithm, it uses a full set of labeled data. There is an existing data set that serves as a training mechanism to teach the algorithm the correct label.
There are six common methods of supervised learning models:
- Linear Regressions
- Logistic Regressions
- Time Series
- Classification or Regression Trees
- Neural Networks
- K-Nearest Neighbor
For example, we can have a labeled data set based on identified breeds of dogs. Labeled photos of a variety of dog breeds such as chihuahuas, Yorkshire terriers, or German shepherds rea integrated into the model. These labeled data teach the algorithm to identify these breeds from another set of photos to predict the right label.
Supervised learning models are the most effective when there are enough existing data points that are readily available for the algorithm to study.
 Unsupervised Learning
Unsupervised Learning
Unsupervised learning models give recommendations generated through extracting meaningful features and patterns within existing data points. They usually are designed to enhance decision-making, processes, and user experiences.
Through a deep learning model, data is then structured even without explanation through neural networks.
Here are a few examples of how unsupervised learning models can organize data:
- Clustering
- Association Analysis
- Anomaly Detection
- Auto-encoders
- Principal Component Analysis
Unsupervised learning models are a good option for when the data points are not fully labeled, too expensive, or hard to acquire. Compared to supervised learning models, the unsupervised learning algorithm model is more comfortable with ambiguity.
The Middle Ground: Semi-Supervised Learning
Semi-supervised learning models marry both approaches to fill in the gaps. Using existing labeled data to help bolster a more expansive set of unlabeled data, it trains data models to be smarter at solving problems.
Doing both processes will ensure that data scientists and businesses will have a holistic view of the project. Through a reward system, data models undergo reinforcement learning. With this, the data mining model becomes more stable and usable in the long term.
A few common examples of common uses for semi-supervised learning models are:
- Speech Analysis
- Webpage Classification
- Annotation
- Facial Expression Recognition
Data scientists who use the semi-supervised model begin with a supervised learning approach before an unsupervised one.
First, relationships become established through the various points of labeled data. Then unsupervised learning models are used to acquire additional insights. While it may take longer than the other two, developing your neural networks is a worthy investment.
Each learning model will have its strengths and weaknesses. Different algorithms learn differently, depending on what resources are made available to the data scientist. They each have different goals and methodologies that contribute to the final project output.
Read more about Data Mining
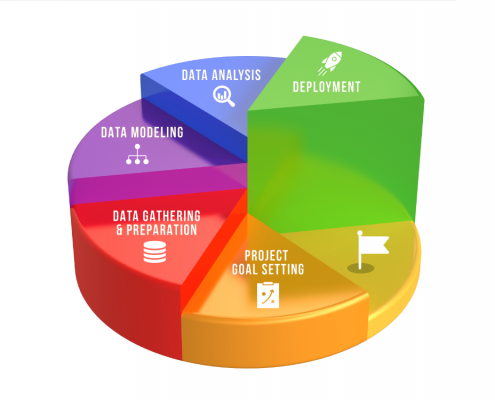 https://heydan.ai/wp-content/uploads/2020/10/5-Data-Mining-Steps.png
750
1000
Hey DAN Online
https://heydan.ai/wp-content/uploads/2020/10/HeyDAN-Logo-2020.png
Hey DAN Online2020-10-14 16:01:482020-10-14 16:02:235 Data Mining Steps
https://heydan.ai/wp-content/uploads/2020/10/5-Data-Mining-Steps.png
750
1000
Hey DAN Online
https://heydan.ai/wp-content/uploads/2020/10/HeyDAN-Logo-2020.png
Hey DAN Online2020-10-14 16:01:482020-10-14 16:02:235 Data Mining Steps https://heydan.ai/wp-content/uploads/2020/10/3-Types-of-Data-Mining-Uses.jpg
750
1000
Hey DAN Online
https://heydan.ai/wp-content/uploads/2020/10/HeyDAN-Logo-2020.png
Hey DAN Online2020-10-02 14:00:002020-10-02 14:15:333 Types of Data Mining Uses
https://heydan.ai/wp-content/uploads/2020/10/3-Types-of-Data-Mining-Uses.jpg
750
1000
Hey DAN Online
https://heydan.ai/wp-content/uploads/2020/10/HeyDAN-Logo-2020.png
Hey DAN Online2020-10-02 14:00:002020-10-02 14:15:333 Types of Data Mining Uses https://heydan.ai/wp-content/uploads/2020/09/What-is-Data-Mining-1.jpg
722
1000
Hey DAN Online
https://heydan.ai/wp-content/uploads/2020/10/HeyDAN-Logo-2020.png
Hey DAN Online2020-09-25 15:00:292020-09-23 16:13:22What is Data Mining
https://heydan.ai/wp-content/uploads/2020/09/What-is-Data-Mining-1.jpg
722
1000
Hey DAN Online
https://heydan.ai/wp-content/uploads/2020/10/HeyDAN-Logo-2020.png
Hey DAN Online2020-09-25 15:00:292020-09-23 16:13:22What is Data Mining
